In my earlier post welcoming IBM Engineering Lifecycle Management (ELM) 7.0.2, I summarized some key changes in 7.0.2 to how the system resolves links between work items in IBM Engineering Workflow Management (EWM) and versioned artifacts in a global configuration context. If you are using global configurations and linking work items, or plan to do so in future, it is critical to understand the changes and new system behaviour, and update your processes — and users — accordingly.
Nick Crossley (esteemed ELM architect) and I recently published the first in a planned series of Jazz.net articles exploring these changes in more detail: Work item linking in a global configuration context: Overview. I’ve included some key points in this post, but encourage you to read the complete article.
Highlights of what is new and different for work item linking in 7.0.2:
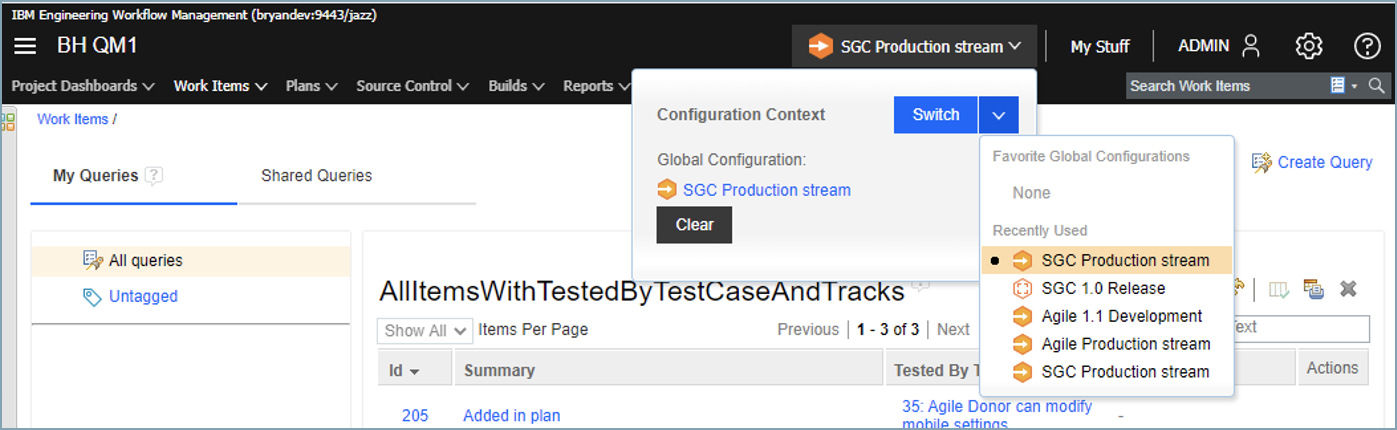
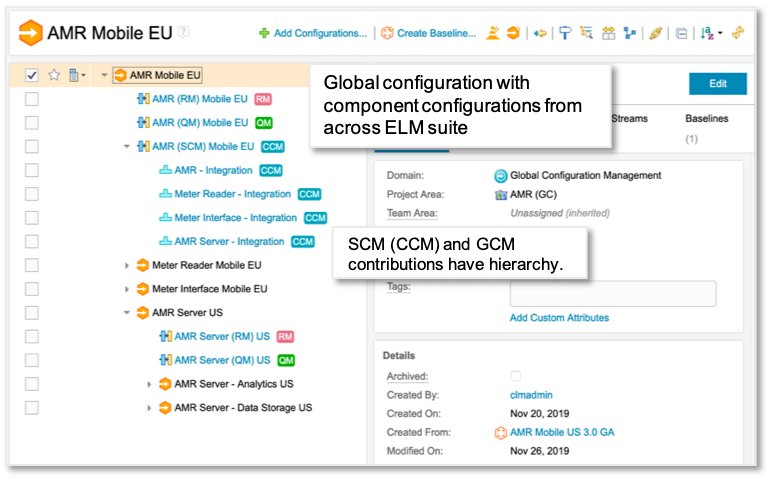
EWM work item editors provide a configuration context menu, which determines the target configuration for outgoing links to versioned artifacts.
Work items are not versioned, and don’t have any configuration context. However, in 7.0.2 you can set the configuration context menu in EWM to define the global configuration (GC) for resolving links to versioned artifacts.

When you set the GC context, all the work item’s outgoing links resolve in that context – regardless of any Link Type/Attribute mappings or release associations to global configurations, which EWM used for link resolution in previous releases. When you work in DOORS Next, Engineering Test Management (ETM), or Rhapsody Model Manager (RMM), the system still uses those settings to determine and resolve incoming work item links; EWM now uses only the configuration context menu setting. (Note: each EWM project area has an option to enable the configuration context menu; if not set, links from the work item resolve as if no configuration is specified.)
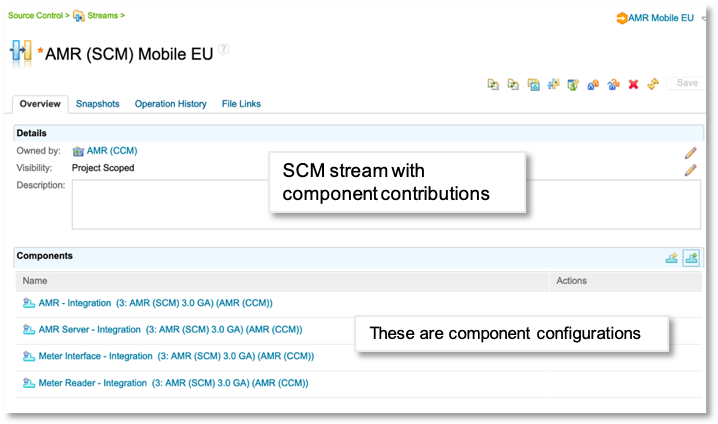
Link EWM releases to global configurations in the GCM application, instead of in EWM.
Before 7.0.2, you associated releases and global configurations in EWM where you defined the releases. In 7.0.2, you define those relationships in the GCM application, where global configurations now have a defined link type for releases. (If you have existing associations in EWM, there is a utility in 7.0.2 to move them to the GCM application.)

You can link multiple releases to a global configuration, and multiple global configurations can link to the same release.
Prior to 7.0.2, the GC-release mapping was one-to-one, which could be problematical if you wanted work item links to resolve in more than one global configuration context – for example, global baselines, different versions, different levels of hierarchy, or personal streams. Now you can link a release to any relevant global configuration, and a global configuration can link to multiple releases, for example, if you have multiple teams working in the context of a broad and deep configuration hierarchy. When you derive a new global configuration from an existing one, release links are initialized to match the parent. You can also define predecessor relationships between releases to easily include work item links from earlier related releases without having to specify each release every time.
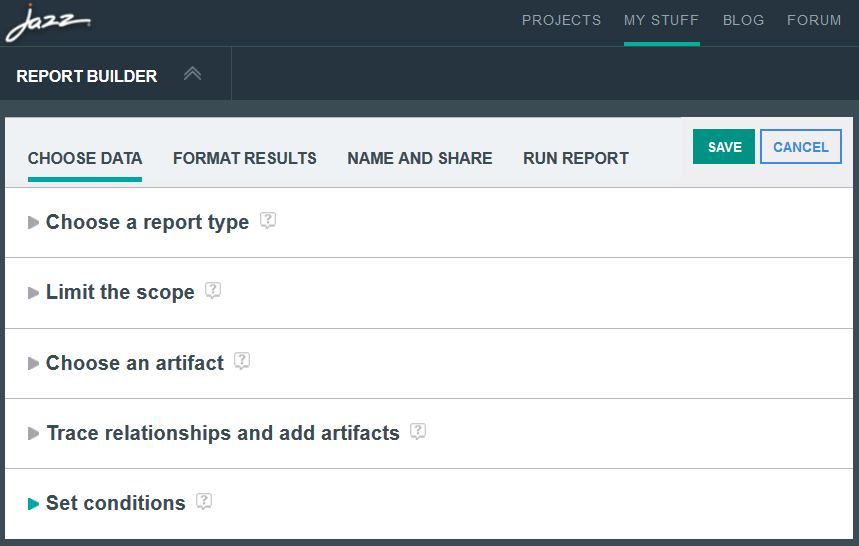
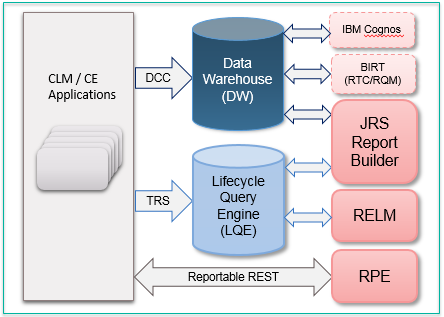
You can filter work item links in Report Builder reports.
By default, LQE includes work items in all global configuration scopes: if a work item links to a versioned artifact in one configuration context, that link would appear in reports for all contexts that include that artifact. In 7.0.2, you can set an option in your report that filters linked work items based on the global configuration-release mappings. Set it in all reports where you want filtering to occur.

If your teams link work items and versioned artifacts in global configurations, ensure you understand the new capabilities and behaviours in 7.0.2 and the impact to administrators and end users. Educate your users on the correct configuration contexts to use and what to expect when creating, viewing, and navigating links in a configuration context.
For more details, please read the Jazz.net article in full, and watch for more in the series! (I’ll announce them here too.)


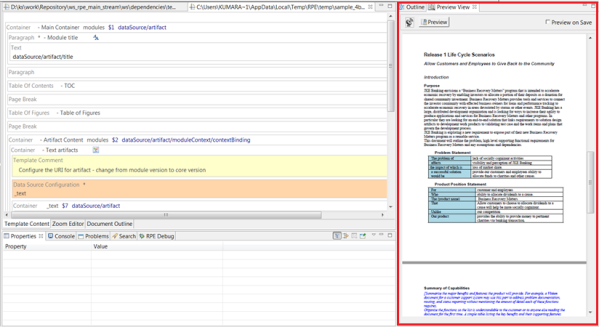
 Only the application for the source artifact actually stores the (outgoing) link. Without CM, the system would also modify the target artifact and store a “back-link” for the incoming link. With CM enabled, the system does not change the target artifact to add the incoming link. Instead, when the user accesses the artifact, the ELM applications use the Link Index Provider (LDX) and internal queries to discover and display the incoming links. So the user still sees all the artifact’s outgoing and incoming links as before, even though the underlying implementation has changed.
Only the application for the source artifact actually stores the (outgoing) link. Without CM, the system would also modify the target artifact and store a “back-link” for the incoming link. With CM enabled, the system does not change the target artifact to add the incoming link. Instead, when the user accesses the artifact, the ELM applications use the Link Index Provider (LDX) and internal queries to discover and display the incoming links. So the user still sees all the artifact’s outgoing and incoming links as before, even though the underlying implementation has changed.